Améliorez un jeu de données

Nous avons jusqu'à présent travaillé sur des jeux de données simples (autrement dit, de faible volume et surtout très propres). Aucune anomalie ni valeur manquante, et les variables sont assez explicites. C'est une situation idéale peu représentative de la réalité professionnelle, où l'on est confronté à des données plus chaotiques.
Dans ce chapitre nous allons travailler sur un "vrai" jeu de données que je trouve passionnant : le dataset des arbres de Paris qui contient des informations sur plus de 200 000 arbres sur Paris intra-muros et sa périphérie proche.
Ce qui est formidable avec ce dataset, hormis de pouvoir visualiser tous les arbres d'une ville comme Paris, c'est qu'il illustre parfaitement les principaux problèmes qu'un data scientist rencontre :
des données manquantes ;
des données aberrantes (outliers) ;
des catégories trop nombreuses ou sous-représentées.
Malheureusement, la page de ce dataset ne fournit pas de description des champs ni d'information sur le mode de récolte des données. Toutefois les noms des champs sont assez parlants et nous nous en contenterons.
Repérez les données manquantes
Lorsqu’il est question de données manquantes pour une variable donnée, on a 3 stratégies possibles :
Ignorer et supprimer tous les échantillons pour lesquels cette valeur manque. Cela vaut seulement si cela ne concerne qu'une petite partie du dataset.
Remplacer les valeurs manquantes par une valeur spécifique qui indique que la valeur n'est pas disponible. Par exemple -1 ou 0 pour des nombres ou None pour une catégorie. On espère alors que le modèle saura prendre en compte l'information.
Inférer les valeurs manquantes à partir des valeurs disponibles, voire des autres variables. On peut par exemple prendre la moyenne des valeurs disponibles ou construire une régression linéaire à partir des autres variables.
Regardons ce qu'il en est sur le dataset des arbres.
Le dataset étant assez riche, on va se limiter aux platanes. Ce qui nous laisse plus de 42 500 arbres pour jouer.
df = df[df.libelle_francais == 'Platane'].copy()La variable stade_de_developpement a 3 350 valeurs manquantes (NaN).
stade_de_developpement
Adulte 21620
Jeune (arbre)Adulte 8356
Jeune (arbre) 5916
NaN 3350
Mature 3346On suppose que la valeur Jeune (arbre)Adulte n'est pas une erreur de saisie mais plutôt une valeur intermédiaire entre les catégories Jeune (arbre) et Adulte . On a donc la graduation : Jeune (arbre) , Jeune (arbre)Adulte, Adultepuis Mature .
À ce stade on peut choisir de simplement supprimer tous les échantillons pour lesquels la valeur stade_de_developpement est absente. Cela ne concerne que 7,8 % des données.
On peut aussi essayer de remédier aux valeurs manquantes en observant la relation entre les mesures des arbres et leur stade de développement. Notre hypothèse est que les arbres Jeune ou Mature sont nettement plus petits que les arbres Adulte .
Le boxplot montre la répartition de la hauteur et de la circonférence par stade de développement.
sns.boxplot(df = df, y="circonference_cm", x="stade_de_developpement")
sns.boxplot(df = df, y="hauteur_m", x="stade_de_developpement")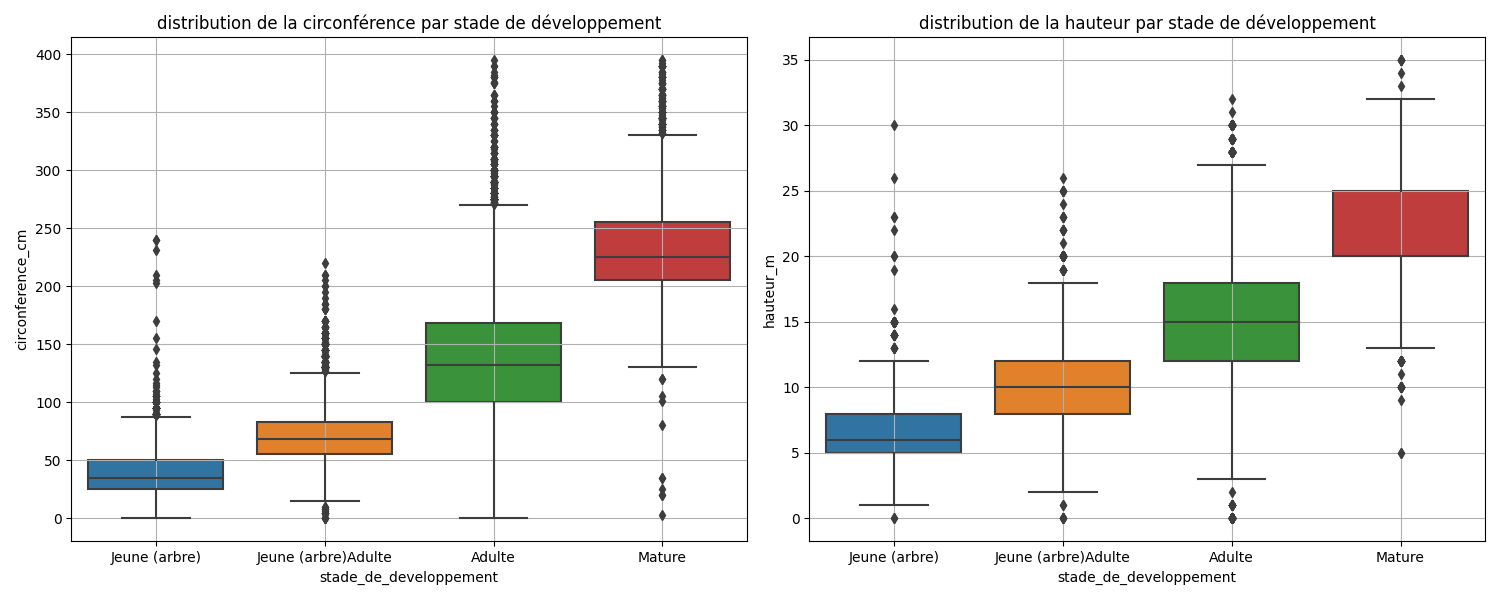
On observe bien une nette différence entre les arbres Jeune ou Mature par rapport aux arbres Adulte .
Donc on peut établir une règle, certes arbitraire, mais qui fait sens pour identifier les arbres Mature ou Jeune parmi les données manquantes.
Par exemple, nous pouvons considérer que les arbres de hauteur_m > 20 et de circonference_cm > 200 ont une forte chance d'être des arbres Mature . Les seuils de 20 et 200 étant directement évalués à partir de la figure précédente.
cond = (df.stade_de_developpement.isna()) & (df.hauteur_m > 20) & (df.circonference_cm > 200)
df[cond].shapeCela identifie 22 arbres que l'on peut maintenant labelliser comme Mature .
Faisons de même pour les arbres Jeune avec des seuils maximum de hauteur et circonférence estimés à partir de la figure précédente.
cond = (df.stade_de_developpement.isna()) & (df.hauteur_m < 8) & (df.circonference_cm < 50)
df[cond].shapeSoit 2 903 arbres que l'on peut maintenant labelliser comme Jeune (arbre) .
Détectez les outliers (données aberrantes)
Contrairement aux données manquantes où l'absence de valeurs saute aux yeux, le cas des outliers (données aberrantes) est plus délicat. Une valeur peut paraître extrême, mais l'est-elle vraiment ?
Un âge de 200 ans est évidemment impossible (pour le moment), mais qu'en est-il d'un âge de 80 ans dans un dataset de coureurs de marathon ? S'agit-il d'une erreur ou bien d'un senior en pleine forme ? Il n'y a pas de moyen d'apporter une réponse systématique à cette question. Cela dépend vraiment du contexte.
Il y a 2 types d'outliers :
Les données vraiment absurdes (200 ans d'âge).
Et les données extrêmes mais qui pourraient se révéler être néanmoins pertinentes.
Mais pourquoi s'inquiéter des valeurs extrêmes si elles sont vraies ?
Les outliers ont une influence directe sur le modèle en biaisant les statistiques de la distribution de la variable.
Prenez le cas de la moyenne de cette suite de chiffres :
moyenne ([-1.2, 0.15, -0.64, 0.46, -1.26, -1.89, -0.34, 0.66, 1.48, -1.26]) = 0.17Mais si on ajoute la valeur 10 :
moyenne ([-1.2, 0.15, -0.64, 0.46, -1.26, -1.89, -0.34, 0.66, 1.48, -1.26, 10]) = 1.06Une valeur extrême peut avoir un fort impact sur la statistique de la variable et donc sur le modèle.
Comment identifier les outliers puis y remédier ?
Visualiser la distribution de la variable par un histogramme ou un boxplot donne déjà une bonne indication de la présence d'outliers.
Traçons par exemple la hauteur et la circonférence des platanes. On trouve un platane de 700 mètres de hauteur et 2 platanes de plus de 10 mètres de circonférence.
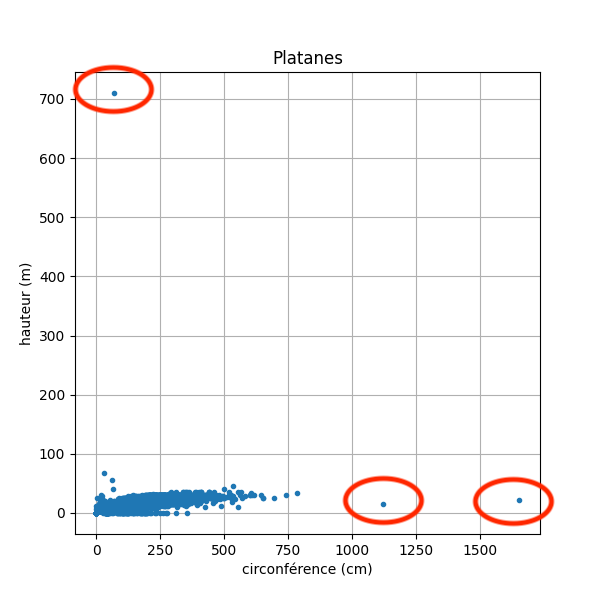
On peut enlever ces 3 échantillons sans se poser trop de questions :
df = df[(df.circonference_cm < 1000) & (df.hauteur_m < 100)].copy()Il existe aussi des techniques éprouvées pour identifier les outliers. Il nous appartiendra ensuite de les traiter en tant que tels ou non. Nous allons calculer un score qui traduit l'écart de la valeur par rapport à la distribution de la variable.
Utilisez la méthode du z-score
Le z-score mesure de combien d'écarts types une valeur est éloignée de la moyenne de la variable. On considère qu'un z-score supérieur à 2 ou 3 correspond à un outlier.
from scipy import stats
df['z_circonference'] = stats.zscore(df.circonference_cm)
df['z_hauteur'] = stats.zscore(df.hauteur_m)Si on trace les histogrammes des z-scores de la hauteur et de la circonférence, on observe que de nombreux échantillons ont un z-score élevé, supérieur à 2 ou à 3 :
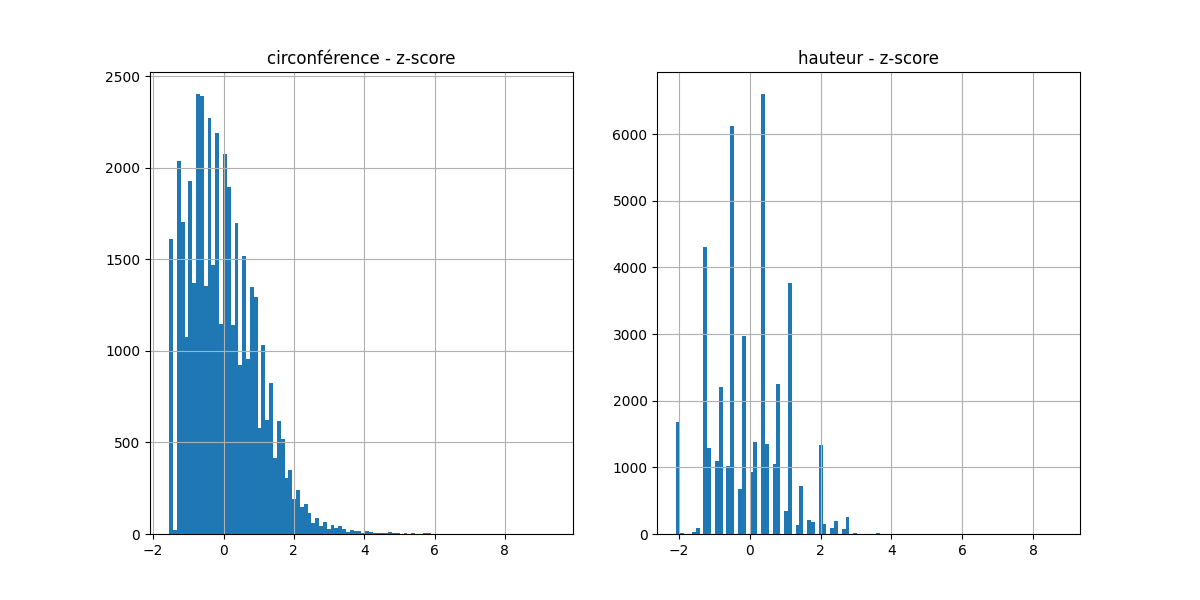
Un seuil z-score à 2 sur la hauteur (respectivement circonférence) détectera 793 échantillons (resp. 1 429) et à 3, 33 échantillons (resp. 349).
Utilisez la méthode de l'IQR
On peut aussi regarder la méthode basée sur l'IQR.
L'IQR est la différence entre le 25e centile (Q1) et le 75e centile (Q3) des données. Les valeurs :
inférieures à Q1 - 1,5 * IQR
ou supérieures à Q3 + 1,5 * IQR
sont considérées comme aberrantes.
import numpy as np
iqr = np.quantile(df.hauteur_m, q=[0.25, 0.75])
limite_basse = iqr[0] - 1.5*(iqr[1] - iqr[0])
limite_haute = iqr[1] + 1.5*(iqr[1] - iqr[0])Ce qui donne -5,5 pour la limite basse (pas très utile vu que les arbres n'ont pas de hauteur négative !) et 30,5 pour la limite haute. Plus intéressant. Pour la circonférence on obtient une limite haute à 305 cm.
En résumé, voici le nombre d'échantillons identifiés comme ayant une valeur aberrante par les méthodes z-score et IQR :
| hauteur | circonférence
zscore < 2 | 793 | 1429
zscore < 3 | 33 | 349
IQR | 44 | 485Donc un grand éventail de résultats selon la méthode et les seuils choisis. À ce stade, le bon choix ne peut se faire qu'à partir d'une connaissance du sujet.

Une fois identifiés, il peut y avoir plusieurs façons moins drastiques de traiter les outliers.
On citera :
Prendre le log de la valeur. Cela réduira fortement la dispersion de la distribution et l'influence des outliers.
Instaurer une règle arbitraire, comme de choisir de fixer une limite supérieure à la variable.
Discrétiser la variable par intervalle en laissant le dernier intervalle ouvert pour inclure les valeurs extrêmes.
Pour discrétiser la variable en un nombre fini d'intervalles, on utilise les méthodes qcut et cut de Pandas.
qcut va scinder la variable en intervalles de volumes sensiblement égaux en fonction de leur fréquence :
pd.qcut(df.hauteur_m, 3, labels=["petit", "moyen", "grand"]).value_counts()
hauteur_m
petit 17875
moyen 12568
grand 12142 cut va scinder les données en intervalles de même taille :
pd.cut(df.hauteur_m, 3, labels=["petit", "moyen", "grand"]).value_counts()
hauteur_m
petit 40058
moyen 2524
grand 3Normalisez les valeurs numériques
Il faut donc normaliser les variables pour qu'elles aient des amplitudes similaires.
Les 2 méthodes de normalisation les plus courantes sont :
Min-Max Scaling (Normalisation).
Z-Score Standardization.
Min-Max Scaling (Normalisation)
X_normalized = (X - X_min) / (X_max - X_min)Les données seront toutes comprises entre 0 et 1.
Z-Score Standardization
X_standardized = (X - X_mean) / X_stddevLes données auront toutes une moyenne nulle et un écart type de 1.
En Python, sur la hauteur et la circonférence des arbres, cela donne :
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['hauteur_standard'] = scaler.fit_transform(df.hauteur_m.values.reshape(-1, 1))
df['circonference_standard'] = scaler.fit_transform(df.circonference_cm.values.reshape(-1, 1)) On peut aussi transformer la variable en prenant son logarithme si elle ne prend que des valeurs positives. Cela va réduire fortement son amplitude sans perte d'information pour le modèle.
df['circonference_log'] = np.log(df.circonference_cm + 1)
df['hauteur_log'] = np.log(df.hauteur_m + 1)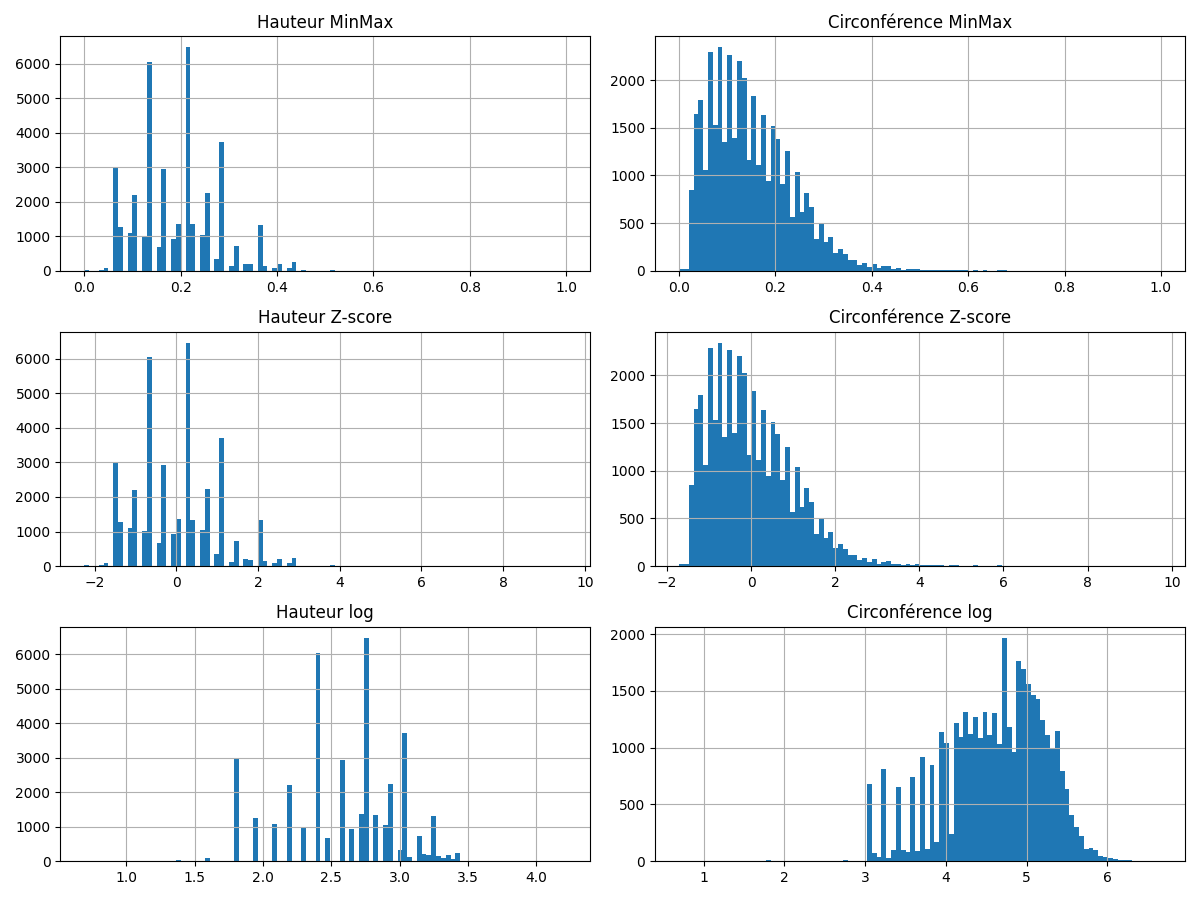
À vous de jouer !

Il se trouve que 1 688 platanes ont une hauteur nulle (égale à 0) et 1 592 ont une circonférence aussi égale à 0.
En ce qui concerne la hauteur, il se peut que cela soit dû à la discrétisation observée précédemment et donc au mode de mesure utilisé. Pour la circonférence par contre, ces valeurs nulles sont plus probablement des valeurs manquantes.
Comment remplaceriez-vous ces valeurs nulles (=0) par des valeurs qui font sens ?
Regardez maintenant les autres principales espèces du dataset (
df.libelle_francais.value_counts()), comme le marronnier ou le tilleul. Ces espèces ont-elles des données manquantes ou des outliers ? Comment les traiterez-vous après les avoir identifiés ?
Une suggestion pour vous guider dans la bonne direction : remplacer les données manquantes par la moyenne des valeurs pour des arbres similaires, soit par espèce soit en faisant une régression linéaire par rapport aux variables qui sont renseignées.
En résumé
Dans ce chapitre nous avons traité 3 des problèmes les plus fréquents que l'on peut rencontrer sur un vrai jeu de données.
Pour remédier aux valeurs manquantes, nous pouvons les remplacer par des valeurs arbitraires ou en fonction des valeurs de la variable en question.
Pour détecter les valeurs aberrantes, on utilise la méthode du z-score ou de IQR.
Et pour remédier aux valeurs aberrantes, nous pouvons discréditer la variable ou forcer une valeur maximum.
Enfin, pour les variables d'amplitude nous pouvons les normaliser, les standardiser ou prendre leur logarithme.
Dans le chapitre suivant nous allons rendre les variables de texte digestes pour les modèles.
