Comprenez le rôle central du jeu de données
Privilégiez une approche data-centric
On peut approcher la construction de modèles performants de 2 façons :
En se concentrant sur les modèles.
Ou en se concentrant sur les données.
L'approche model-centric est l'approche la plus courante et la plus enseignée. On vous fournit un dataset explicite et propre, à vous de créer un modèle performant.
Dans le monde réel, choisir un modèle et l'optimiser par rapport à un dataset donné est un problème somme toute résolu.
Les types de modèles les plus efficaces sont connus et disponibles :
soit sous forme open source (via des librairies de type scikit-learn, TensorFlow, etc.) ;
soit via des services cloud d'auto ML (Vertex AI, SageMaker, etc.).
Cette approche, plus centrée sur les données que sur le modèle, recouvre une série de pratiques dont la finalité est de booster les performances du modèle en manipulant les données.
L'idée principale sera d'être attentif :
à la qualité du jeu de données : valeurs manquantes, outliers, mauvais étiquetage, biais de représentation… ;
aux erreurs du modèle. Comprendre pourquoi certains échantillons posent problème et transformer ces caractéristiques en variables que le modèle puisse apprendre.
Dans cette troisième partie du cours, nous allons donc nous concentrer sur la partie ‘données’ du couple données - modèle.
Trouvez des jeux de données
Avant de nous attacher à améliorer la qualité ou transformer un jeu de données, regardons où l'on peut trouver des jeux de données.
En 2018, Google lance son moteur de recherche dédié aux jeux de données : Dataset Search.
Kaggle, la plateforme de compétition de Machine Learning, offre aussi de nombreux datasets.
Nous avons déjà vu les sites dédiés au ML comme UCI.
Les sites institutionnels ont souvent une politique d'open source. On citera les portails de Paris, Londres, ou celui de Rome ainsi que celui des institutions européennes.
Les agences scientifiques, ONG et agents nationaux : ADEME, EdF, WWF et GBIF sur la biodiversité.
BigQuery, un service de big data de Google Cloud met à disposition gratuitement des datasets extrêmement intéressants et de grand volume.
Enfin, les librairies elles-mêmes :
scikit-learn met à disposition des datasets simples (toy dataset) ou plus complexes (real world) ;
ainsi que statsmodels et le package R Datasets.
Vous avez donc le choix pour vous familiariser avec des types de données et des tâches variées de Machine Learning.
Créez votre propre dataset
Dans le chapitre sur le clustering, nous avons construit nous-mêmes un dataset de travail propre au problème de partitionnement automatique.
Scikit-learn offre d'autres méthodes de construction de dataset qui sont utiles pour des tâches de classification, de régression ou de clustering. Nous avons vu make_blobs() pour le clustering, mais il y a aussi make_regression et make_classification pour créer des datasets adaptés respectivement à la régression et à la classification.
D'autres méthodes permettent de générer des données plus complexes, notamment qui ne soient pas linéairement séparables (on ne peut pas tracer une droite séparant les différentes catégories de nuages de points).
À vous de jouer !

Regardez la méthode make_classification et générez un dataset avec les caractéristiques suivantes :
classification binaire (n_classes) ;
1 000 échantillons (n_samples) ;
3 variables (n_features) toutes 2 utiles (n_informative = 0, n_redundant = 0).
Ensuite, entraînez une régression logistique sur tout le dataset et observez les performances du modèle.
Plus challenging pour la régression logistique, utilisez make_circles et make_moons pour générer des datasets de la forme :
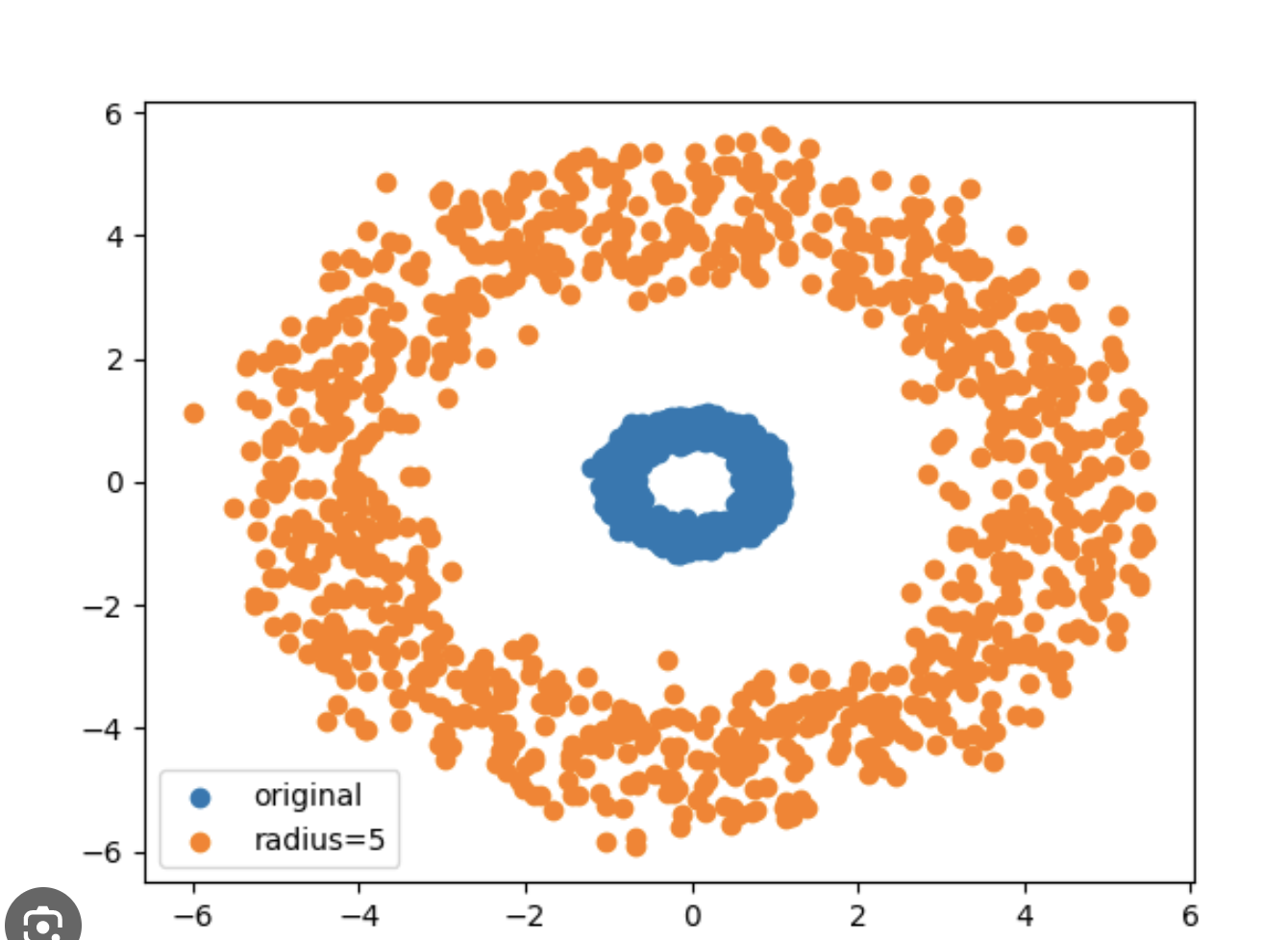
et de la forme :
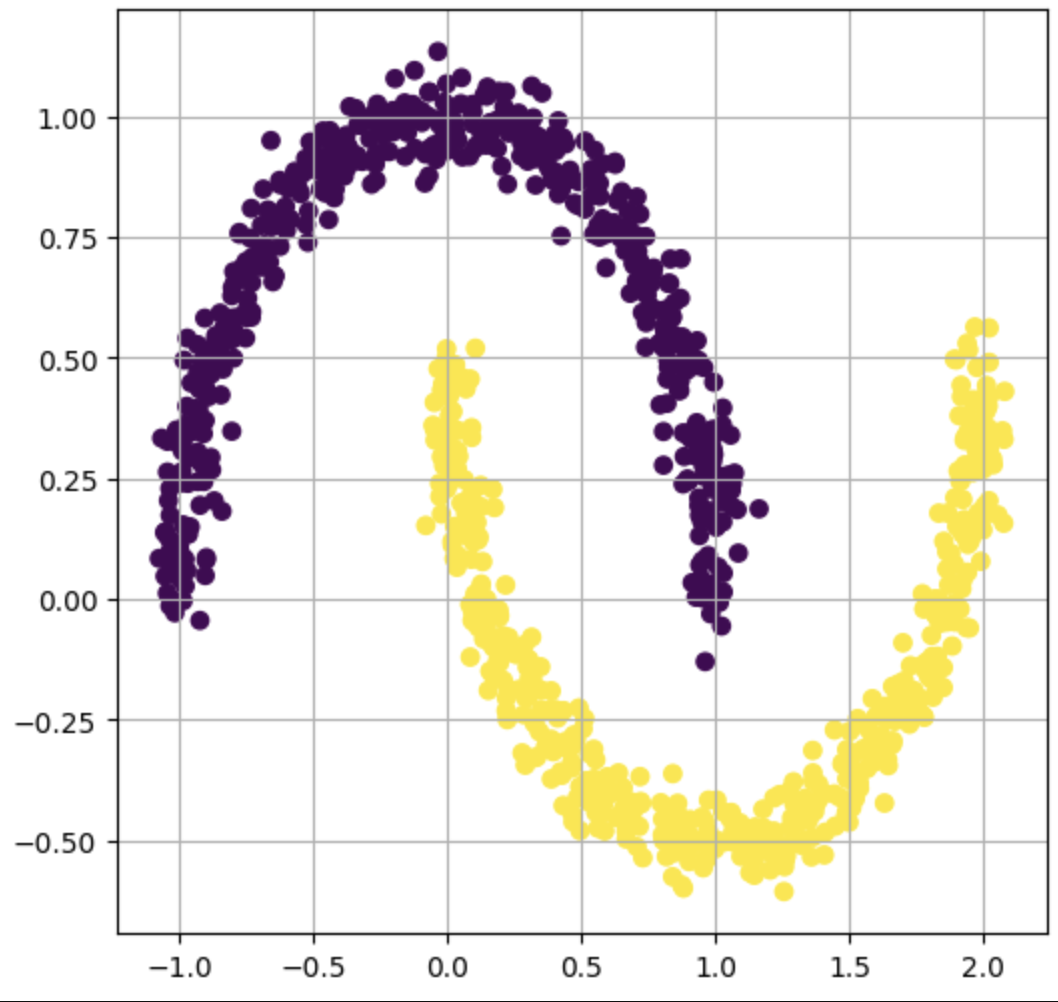
Puis entraînez une régression logistique et observez la performance du modèle. Elle devrait chuter car les nuages des échantillons des différentes catégories ne sont pas linéairement séparables.
Vous pouvez générer un dataset de type moon avec par exemple :
data = datasets.make_moons(n_samples=n_samples, noise=0.05)et de type circle (cercle) avec :
data = datasets.make_circles(n_samples=n_samples, factor=0.5, noise=0.05)En retour vous avez :
X = data[0] l'array numpy de dimension 2 des prédicteurs
et y = data[1] l'array numpy des catégories de chaque échantillon.
Réduisez l'influence des préjugés dans les prédictions du modèle
L'IA est maintenant présente dans tous les secteurs. Il nous faut nous assurer que les modèles que nous construisons ne sont pas biaisés.
Un modèle biaisé est un modèle dont les prédictions sont systématiquement distordues. Avec comme conséquence directe un risque de décisions qui sont systématiquement inéquitables ou inexactes.
La première cause de biais est le fait d'un mauvais échantillonnage des données d'entraînement. Par exemple, si un sondage d'opinion n'interroge que les utilisateurs d'iPhone, les résultats ne reflètent sûrement pas l'opinion de toute la population.
Plus concrètement…
En ressources humaines, quand les données historiques d'entraînement contiennent plus d'hommes que de femmes pour un poste donné (ou vice versa), un modèle de présélection de candidats aura tendance à favoriser les profils d'hommes pour ce poste. D'ou une discrimination avérée bien qu'involontaire.
Dans le cadre de la sécurité bancaire, un modèle entraîné principalement sur des fraudes en ligne sera incapable de détecter d'autres types de fraude (en personne ou internes).
Néanmoins le biais n'est pas toujours dû à une sous-représentation d'une catégorie d'événement.
Pour atténuer le biais, il faut donc s'assurer de l'exhaustivité des valeurs des variables prédictrices ou cibles, et mettre en place des stratégies de remédiation. En ce qui concerne les LLM, vos prompts sont en fait automatiquement enrichis d'instructions permettant de limiter le biais intrinsèque des modèles.
En résumé
Les gains de performance potentiels sont obtenus en travaillant sur les données d'entraînement.
Scikit-learn offre de multiples fonctions pour créer des jeux de données de classification.
Si l'on n'y prête pas attention, un modèle de prédiction peut reproduire des à-prioris nuisibles.
Dans le prochain chapitre nous allons attaquer deux des principaux problèmes inhérents aux jeux de données : les données manquantes et les données aberrantes.
